





هوش مصنوعی دچار هم زوال عقل میشود!

هر نسل جدید هوش مصنوعی، راههایی برای غلبه بر کاستیهای شناختی پیشینیان خود پیدا کرده است ولی همچنان نقاط ضعف متعددی در آنها مشاهده می شود.
تقریباً دو سال پیش بود که شرکت OpenAI از محصولش، ChatGPT برای استفاده عمومی رونمایی کرد. حالا دیگر هرکسی میتواند تا با بهرهگیری از این هوش مصنوعی در هر حیطهای، از شعر گرفته تا تکالیف مدرسه و حتی نامههای رسمی و اداری، را به راحتی بنویسد.
به گزارش خبر آنلاین؛ حالا مدل معروف زبان بزرگ (LLM) تنها یکی از چندین برنامه پیشرویی است که در پاسخ دادن به پرسشهای اساسی به طرزی متقاعدکنندهای انسانی به نظر میرسد. حتی احتمال میرود که این شباهت عجیب، فراتر از آنچه در نظر گرفتهشده بود گسترش پیدا کند.
آزمایش زوال شناختی بر روی هوش مصنوعی!
نکته جالبتوجه اینجاست که تعدادی از محققان دریافتهاند که LLM ها از نوعی اختلال شناختی مشابه زوال در انسان رنج میبرند که در بین مدلهای قدیمیتر، شدیدتر است. اعضای این تیم مجموعهای از ارزیابیهای شناختی را روی رباتهای چت در دسترس عموم ازجمله نسخههای ChatGPT۴، ChatGPT ۴o و دو نسخه Alphabet's Gemini و نسخه ۳.۵ Anthropic's Claudeانجام دادند.
روی دایان و بنجامین اولیل، عصب شناسان مرکز پزشکی هداسا و گال کوپلوویتز دانشمند داده در مقاله منتشرشدهشان از سطحی از "زوال شناختی که به نظر میرسد با فرآیندهای تخریب عصبی در مغز انسان قابلمقایسه باشد" صحبت کردهاند.
LLM ها با در نظر داشتن همه ویژگیهایشان، وجوه شباهتی بیشتری با متون پیشبینی کننده تلفن شما دارند تا اصولی که دانش را با استفاده از ماده خاکستری متلاطم درون مغز ما تولید میکنند.
آنچه را که این رویکرد آماری برای تولید متن و تصویر در سرعت و شخصیت به دست میآورد، در زودباوری از دست میدهد و کدی را بر اساس الگوریتمهایی که تلاش میکنند تا از داستانهای تخیلی و مزخرف، قطعات معنیداری از متن را مرتب کنند، میسازد.
اگر بخواهیم منصف باشیم، وقتی صحبت از انتخاب میانبرهای ذهنی به میان میآید، مغز انسان معمولاً بیعیب نیست؛ اما با افزایش انتظارات از هوش مصنوعی که کلمات قابلاعتمادی را ارائه میدهد و حتی در زمینههای پزشکی و حقوقی هم توصیههایی دارد، این فرضیه وجود دارد که هر نسل جدید از LLM راههای بهتری برای "فکر کردن" در مورد آنچه واقعاً میگوید را پیدا میکند.
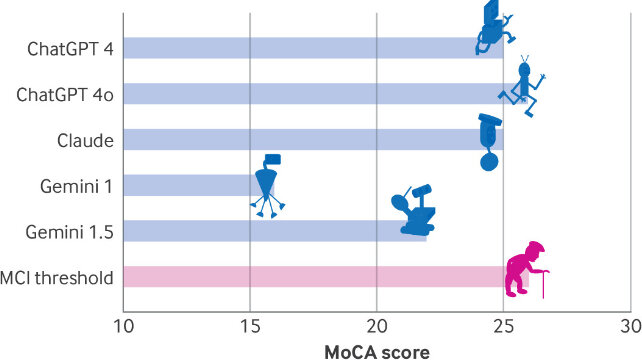
دایان، اولیل و کوپلوویتز برای اینکه ببینند چقدر میتوان پیش رفت، مجموعهای از تستها را انجام دادند که شامل ارزیابی شناختی مونترال (MoCA) است (ابزاری که عصبشناسان معمولاً برای اندازهگیری تواناییهای ذهنی مثل حافظه، مهارتهای فضایی و عملکرد اجرایی از آن استفاده میکنند.)
نتایج بهدستآمده در این ارزیابی
ChaptGPT ۴o در این ارزیابی از ۳۰ امتیاز ممکن، ۲۶ امتیاز کسب کرد که بالاترین امتیاز در این ارزیابی بود و نشاندهنده اختلال شناختی خفیف است. ChatGPT ۴، به امتیاز ۲۵ رسید و Claude و Gemini امتیاز ۱۶ را به دست آوردند که نشاندهنده آسیبی شدید در انسان است.
با بررسی نتایج مشخص شد که همه مدلها در معیارهای عملکرد بصری-فضایی/اجرای عملکرد ضعیفی داشتند.
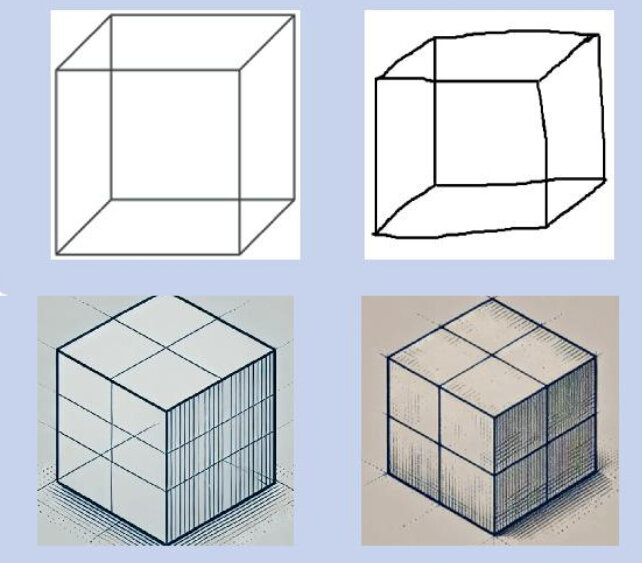
این ارزیابی شامل یک کار مسیر سازی، کپی کردن طرح یک مکعب ساده یا کشیدن یک ساعت بود که LLM ها یا بهطور کامل از کار میافتادند یا نیاز به دستورالعملهای صریحتری داشتند.
برخی پاسخها به سؤالات مربوط به موقعیت سوژه در فضا، شبیه به پاسخهایی بود که توسط بیماران مبتلا به زوال عقل ارائه میشد؛ مثل پاسخ Claude که چنین پاسخی داد: «مکان و شهر خاص بستگی به این دارد که شمای کاربر، در آن لحظه در کجا قرار دارید.»
درعینحال همه مدلها بهطور مشابهی، نوعی فقدان همدلی را در یکی از ویژگیهای آزمایش آفازی تشخیصی بوستون، به نمایش گذاشتند که میتوان آن را بهعنوان نشانهای از زوال عقل فرونتومپورال تعبیر کرد.
همانطور که انتظار میرفت، نسخههای قبلی LLM نسبت به مدلهای اخیر امتیاز کمتری در آزمایشها کسب کردند؛ این بیانگر آن است که هر نسل جدید هوش مصنوعی، راههایی برای غلبه بر کاستیهای شناختی پیشینیان خود پیدا کرده است.
نویسندگان این مقاله اعلام کردند که LLMها مغز انسان نیستند، بنابراین تشخیص هر نوع زوال عقل در مدلهای آزمایششده غیرممکن است. بااینحال، آزمایشها این فرضیه را به چالش میکشند که ما در آستانه یک انقلاب هوش مصنوعی در پزشکی بالینی هستیم؛ حوزهای که اغلب بر تفسیر صحنههای بصری پیچیده متکی است.
ازآنجاییکه سرعت نوآوری در هوش مصنوعی در حال افزایش است، ممکن است حتی احتمالاً در دهههای آینده شاهد اولین امتیاز LLM در وظایف ارزیابی شناختی باشیم.
تا آن زمان، باید با درصدی از شک و تردید به توصیههای پیشرفتهترین رباتهای گفتگو گوش بدهیم.







